Capital Reader
An AI-powered reading platform for Marx's economic texts
An intelligent research tool that combines a 49,000+ chunk multilingual corpus with LLM-driven analysis to enable deep, evidence-based reading of Marx's Capital and related manuscripts.
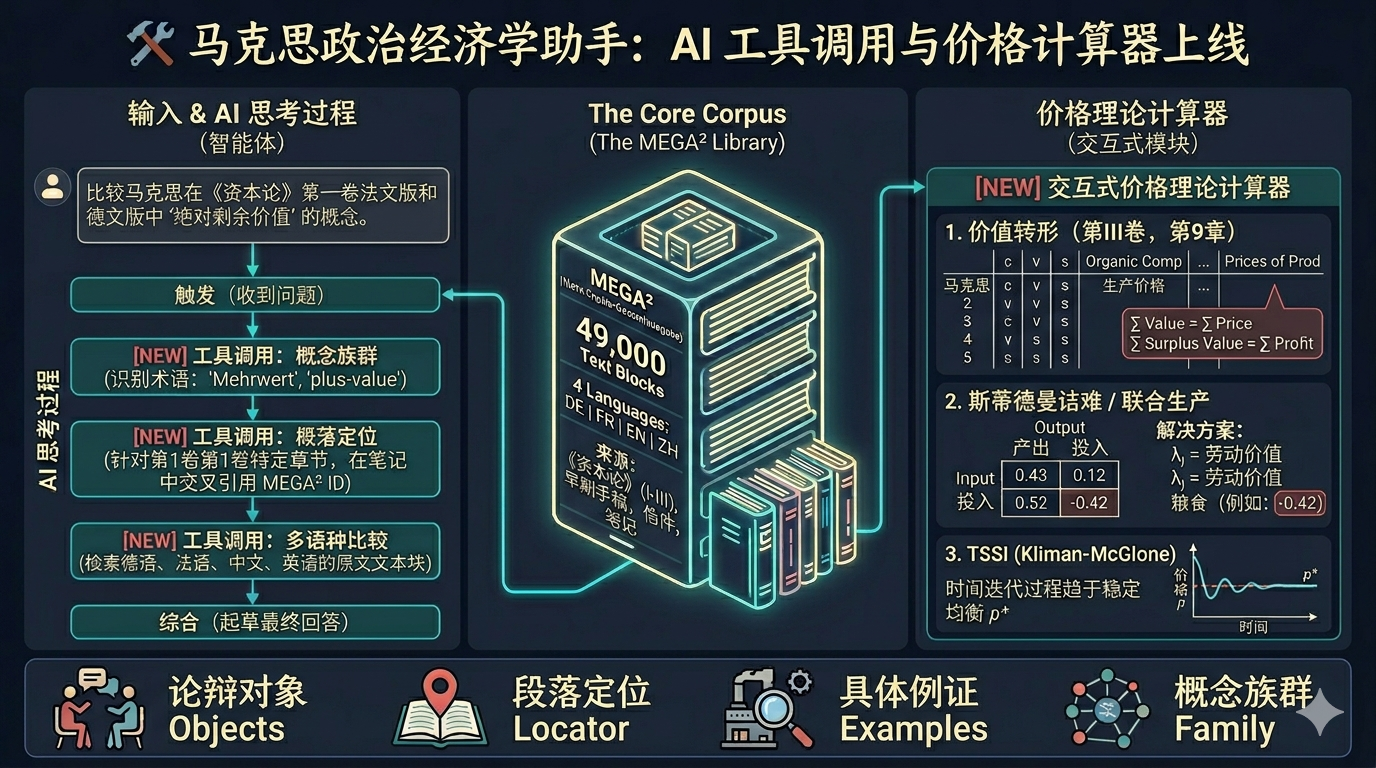
What it does
Capital Reader lets you ask questions about Marx's economic texts in natural language. It retrieves relevant passages from a multi-source corpus — spanning Chinese, German, and French editions — and generates answers grounded in textual evidence, complete with source citations and page references.
Unlike generic AI chat, every answer is anchored to specific passages from the original texts, and users can inspect the evidence directly.
Corpus
The platform draws from six primary sources:
- Das Kapital Vol. I–III — Chinese edition (人民出版社), German edition (MEW)
- Das Kapital Vol. I — Chinese translations of the German first edition (MEGA² Vol. 42) and French edition (MEGA² Vol. 43)
- 1857–1858 Economic Manuscripts — Chinese edition (MEGA² Vol. 30–31)
- 1861–1863 Economic Manuscripts — Chinese edition (MEGA² Vol. 32–36)
Analysis Tools
Beyond Q&A, the platform includes 11 specialized text analysis tools:
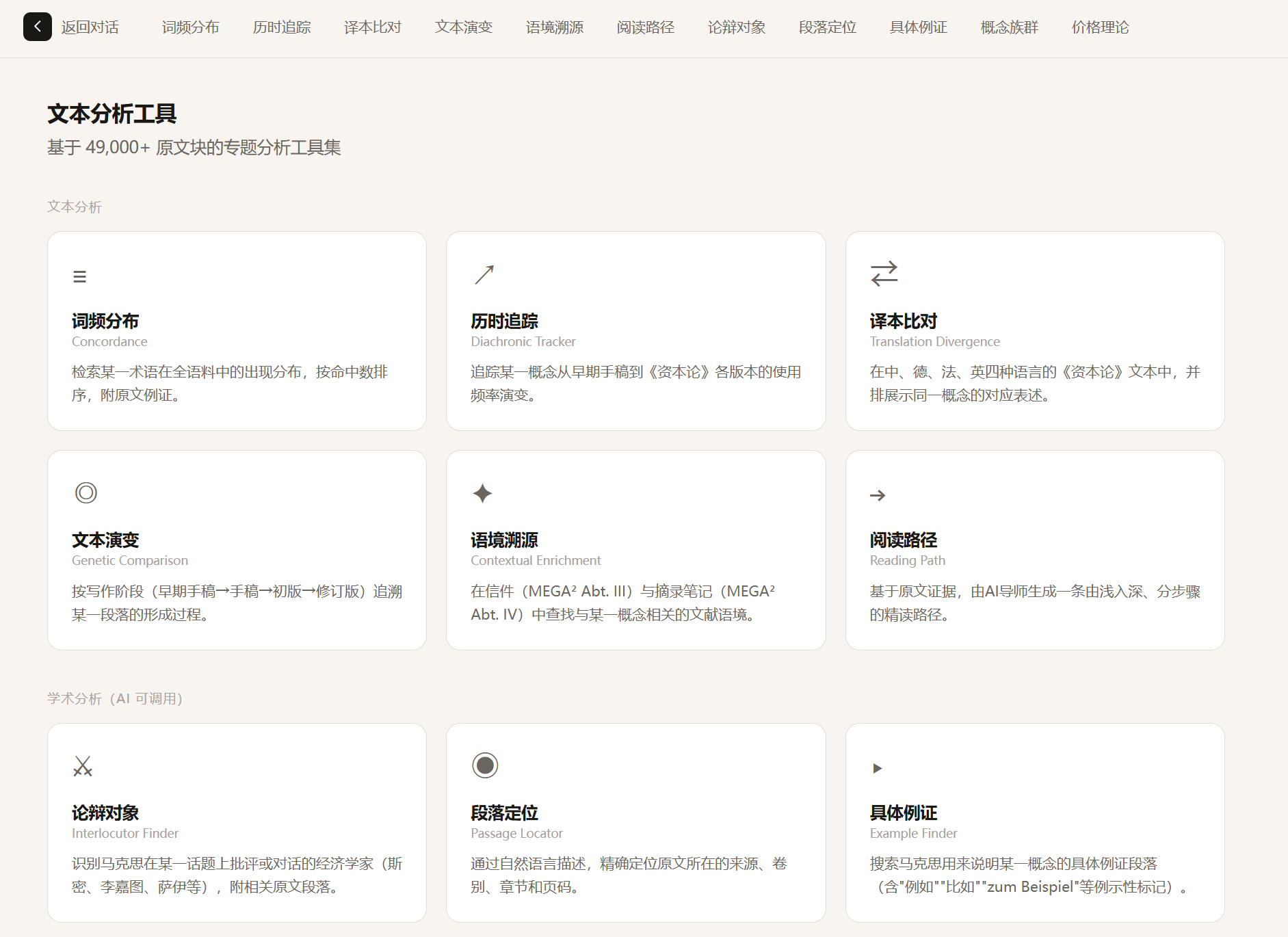
| Tool | Purpose | |------|---------| | Concordance | Term frequency distribution across the entire corpus | | Diachronic Tracker | Track how a concept's usage evolves from early manuscripts to final editions | | Translation Divergence | Side-by-side comparison across Chinese, German, French, and English texts | | Genetic Comparison | Trace how a passage developed through successive writing stages | | Contextual Enrichment | Find related context from Marx's letters and excerpt notebooks | | Reading Path | AI-guided step-by-step deep reading paths | | Interlocutor Finder | Identify which economists Marx is critiquing on a given topic | | Passage Locator | Locate specific passages by natural language description | | Example Finder | Search for concrete examples Marx uses to illustrate a concept | | Concept Cluster | Expand a core concept into a network of related terms with corpus frequencies | | Price Theory Calculator | Interactive computation for the transformation problem, Steedman critique, and TSSI |
Concordance — Term Frequency Distribution
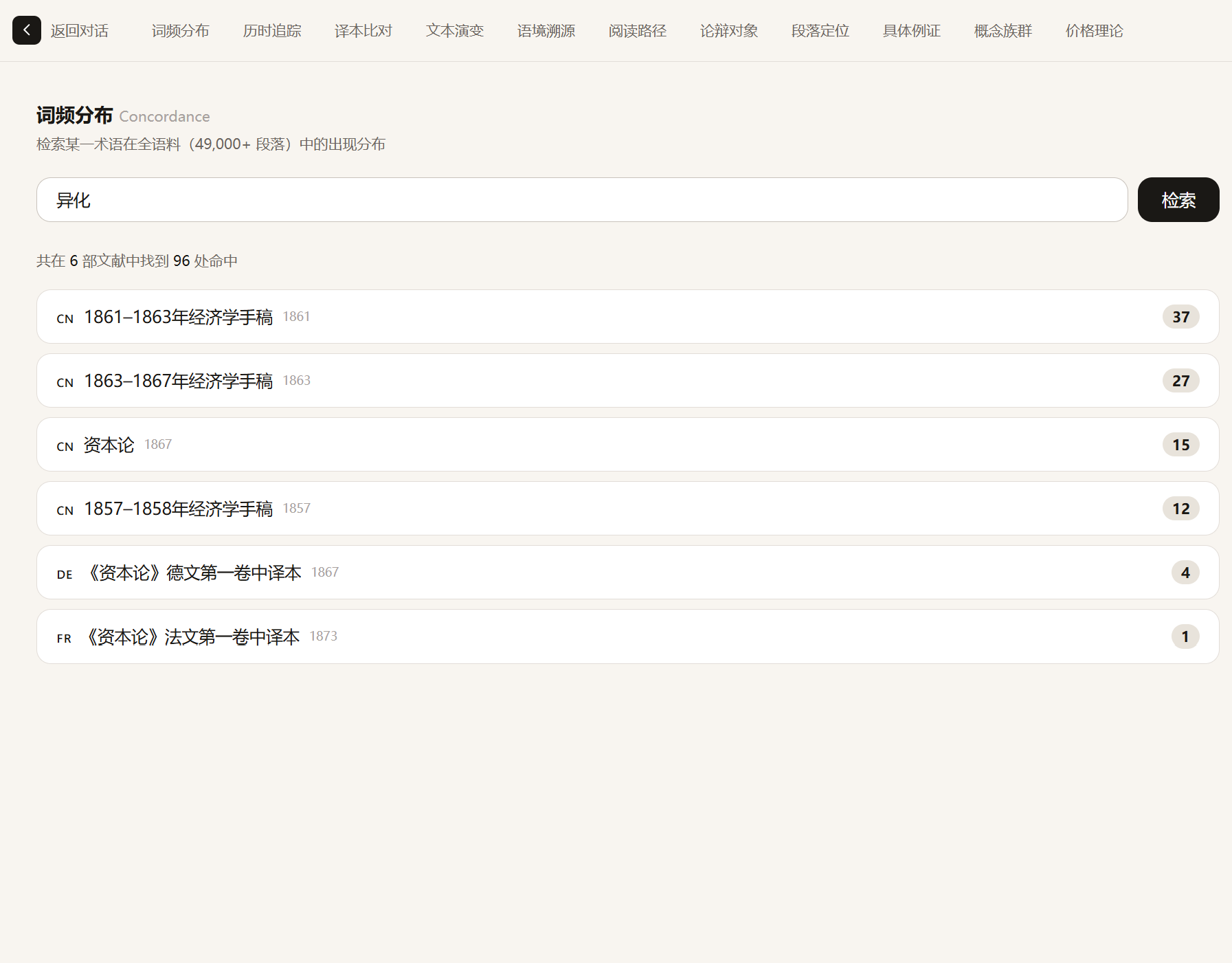
Contextual Enrichment — Multilingual Cross-Reference
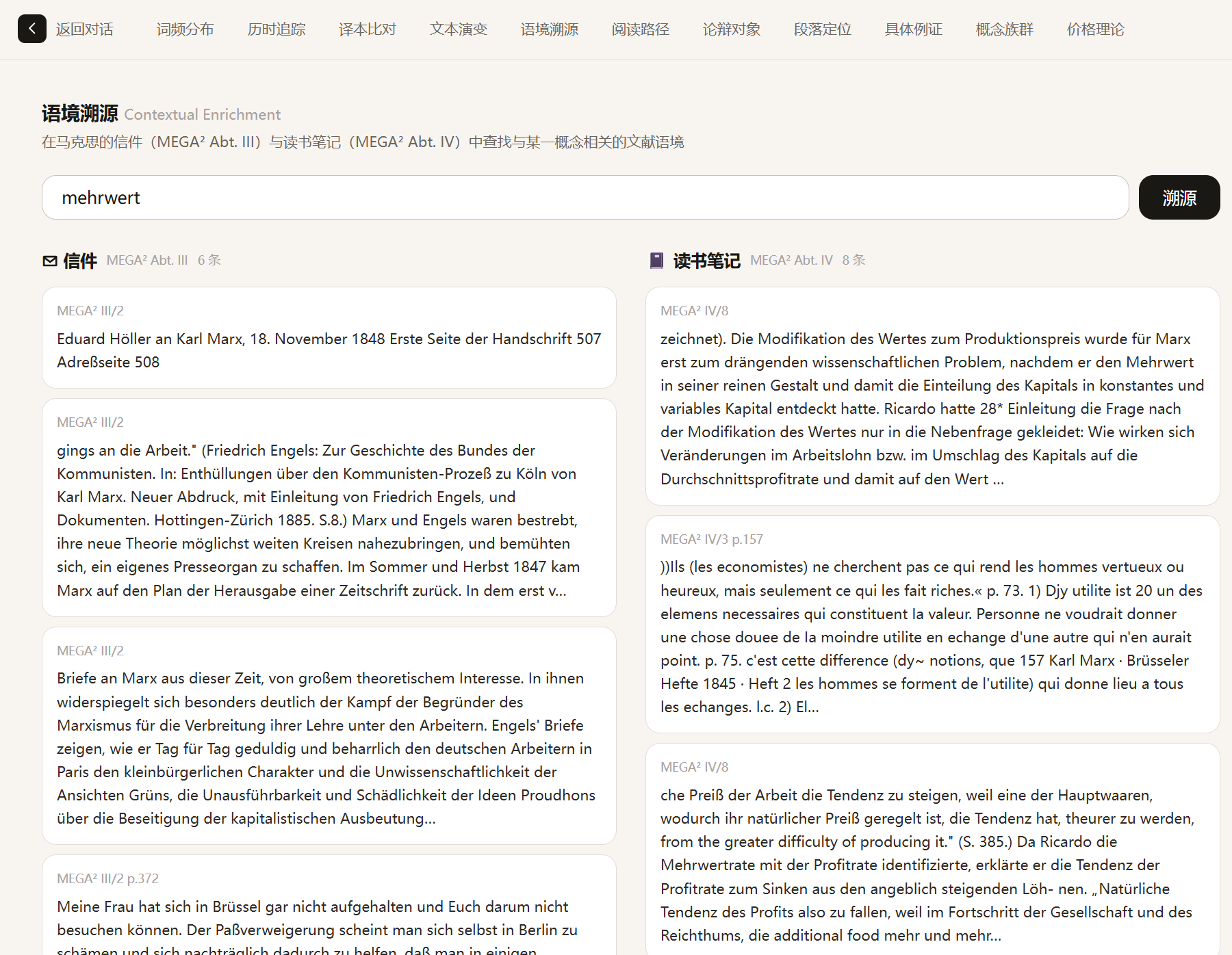
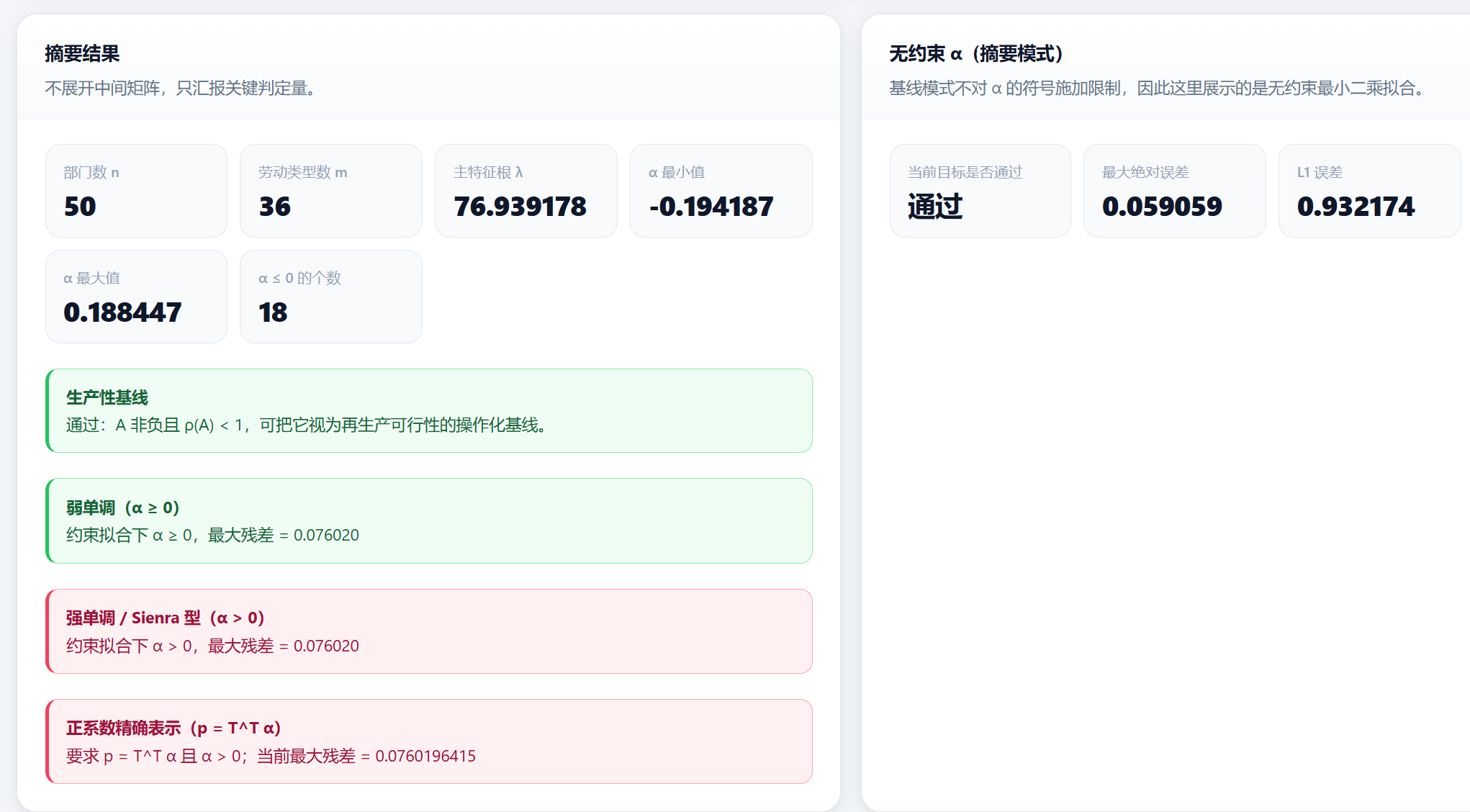
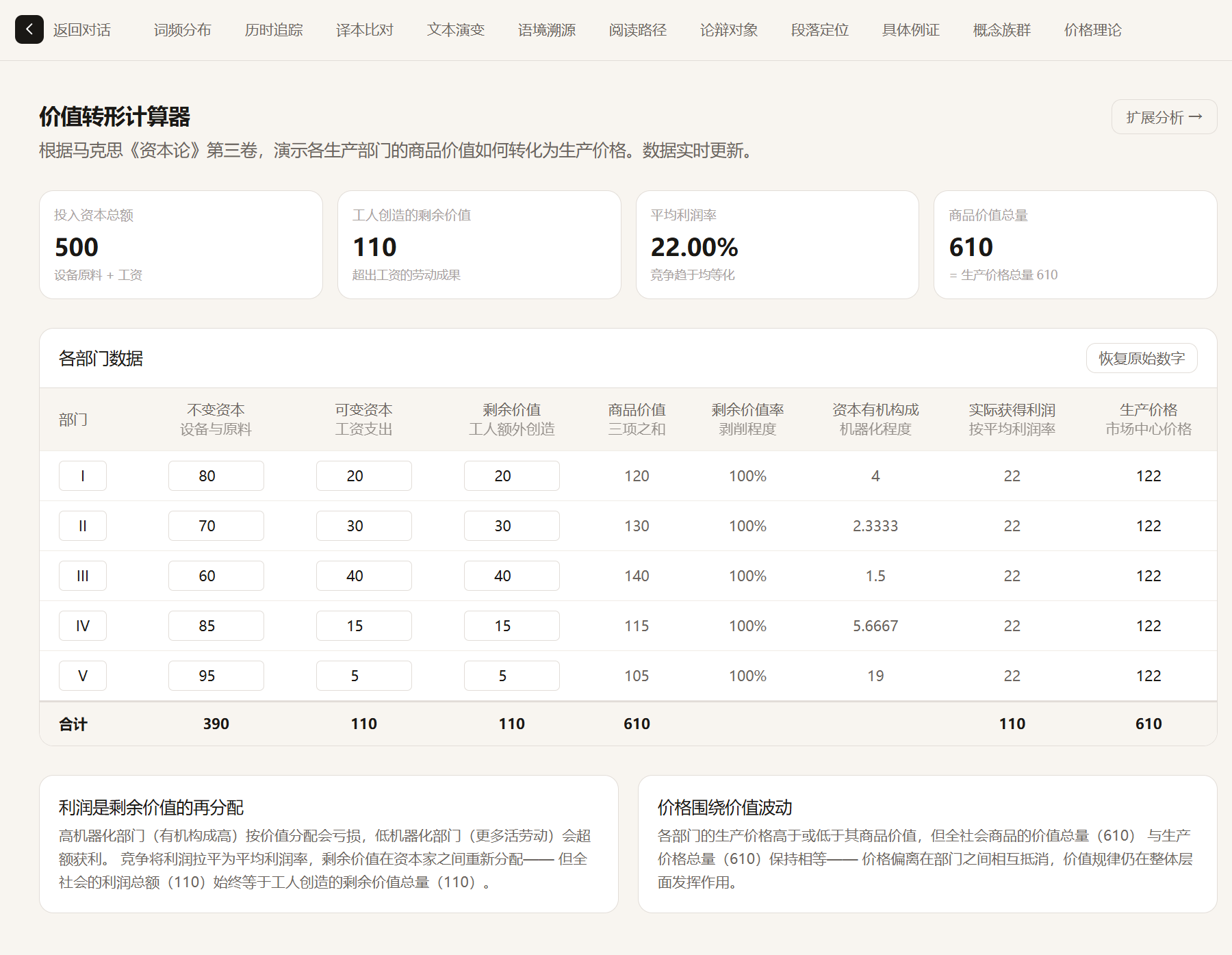
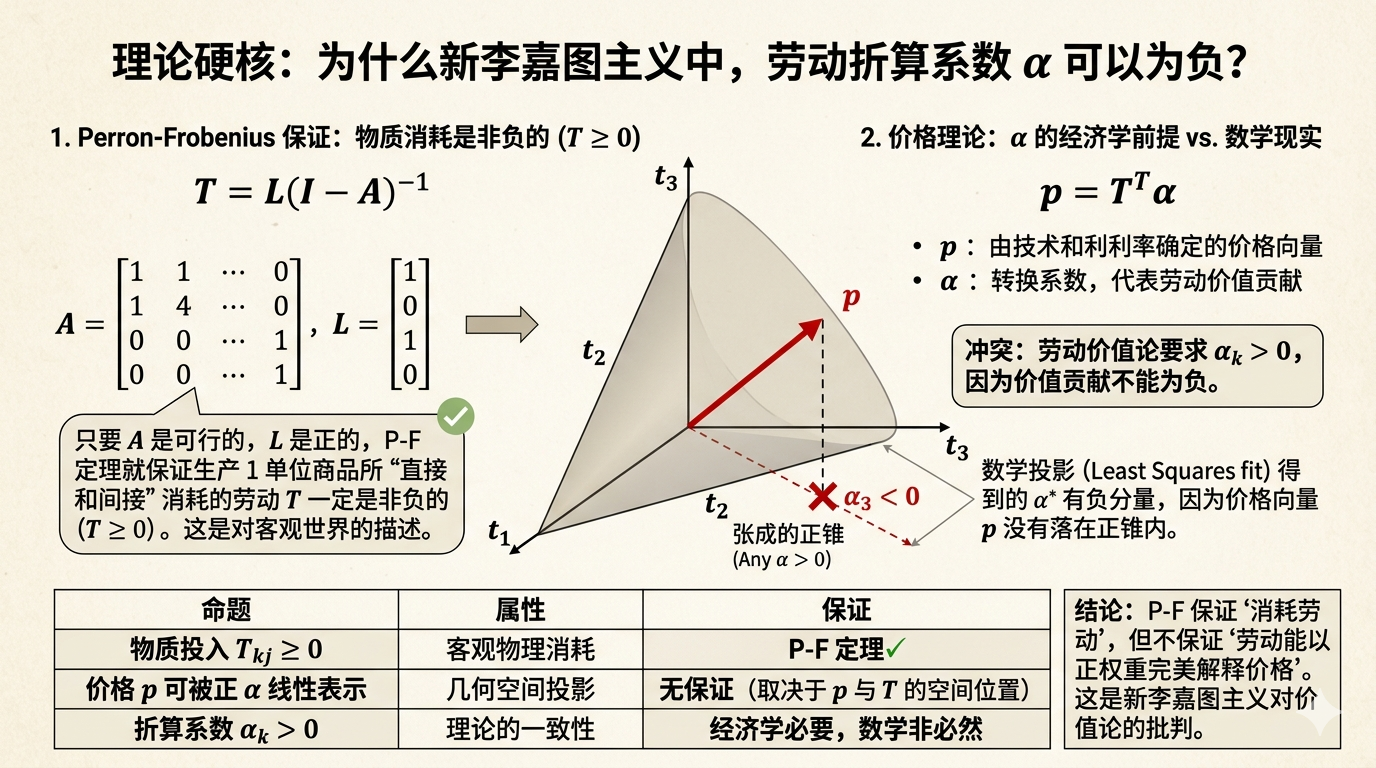
Price Theory Calculator
Interactive computation for the transformation problem with real-time results:
Technical Architecture
- Frontend & API: Next.js 15 (App Router), React 19, TypeScript, Tailwind CSS
- LLM Integration: DeepSeek API with streaming (SSE), configurable model
- Retrieval Pipeline: 4-stage process — planning → retrieval → evidence gating → answer generation
- Data Processing: Python (PyMuPDF) for PDF-to-JSONL ingestion, gzip compression for deployment
- Deployment: Vercel (standalone build, ~85 MB including compressed corpus)
- Knowledge Base: Structured JSON covering 28 concepts, 82 argument steps, and 40 critical issues across all three volumes